
-
Products and Technology
By Category
-
Groups
Activity Groups
Industry Groups
Influence and Feedback Groups
Interest Groups
Location Groups
Customer Only Groups
- Developers
- Partners
- Events
- Help Center
- Topic Pages
-
Explore SAP
Products
- Autonomous Enterprise
- Artificial intelligence
- Data and analytics
- Autonomous Suite
- Technology platform
- Transformation management
- Midsize business solutions
- Financial management
- Spend management
- Supply chain management
- Human capital management
- Customer experience
- Enterprise resource planning
- Business network
- Sustainability management
- SAP Store
- Try SAP
- View all industries
- Partners
- Services
Learning and Support
-
- Products and Technology
- Groups
- Developers
- Partners
- Events
- Help Center
- Topic Pages
-
Explore SAP
- Explore SAP
-
Products
- Products
- Autonomous Enterprise
- Artificial intelligence
- Data and analytics
- Autonomous Suite
- Technology platform
- Transformation management
- Midsize business solutions
- Financial management
- Spend management
- Supply chain management
- Human capital management
- Customer experience
- Enterprise resource planning
- Business network
- Sustainability management
- SAP Store
- Try SAP
- View all industries
- Partners
- Services
- Learning and Support
- About
- SAP Community
- Products and Technology
- Technology
- Technology Blog Posts by SAP
- Auto-generating HANA ML CAP Artifacts from Python
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Introduction
In this blogpost I will walk through the steps which are now possible due to the recent enhancements in SAP HANA Cloud Machine Learning Python Client API and demonstrate how a Data Scientist working in Python can generate SAP HANA Machine Learning artifacts for a CAP project consumed by a developer. This helps building a SAP BTP Intelligent Data Applications much faster with reduced custom code development.
This is "behind the scenes" for content showcased at Sapphire 2023: Building Intelligent Apps with SAP HANA Cloud.
HANA ML Python Client API already provides artifact generation capabilities for ABAP, AMDP, HANA. With the latest release there is specialized support for artifacts required for Cloud Application Programming(CAP).
This blogpost is a based on series of blogposts from frank.gottfried and wei.han7 which describes the same overall flow, with the difference that here I highlight the new enhancements released in hana-ml 2.17 which provides added auto-generation functionality specific for CAP application development and recent additions in Business Application Studio which make the flow more seamless.
The key enhancements for CAP are Extended auto-generated code for :
- HANA ML Stored Procedures for consumption so developers not longer need to write custom wrappers
- Service Entities which enable CAP to generate the appropriate CDS entries for the necessary hdbtables and hdbviews
- Catalog Service for the Node.js service to enable auto-generated OData endpoints
The generated artifacts are the codes for stored procedure, grants and synonyms but not the ML Models itself. For this the ML Training procedure needs to be called on the target HDI container for the model creation. Subsequently the inference can be called by calling the predict procedure or apply function as desired.
Developing Intelligent Data Apps via CAP
Project Development Overview
The capabilities described here are useful when the ML development is done in python to ease the ML modeling process for the Data Scientist.

If the chosen architecture for your productive application which embeds these ML capabilities is based on CAP and you want to embed the corresponding ML artifacts in the HDI container instead of providing a separate python runtime to manage ML artifacts. This facilitates the management of all application artifacts via CAP, while the Data Scientist can continue to develop in their preferred python environment.

Full Stack CAP Application including Machine Learning Models
An alternative architecture option, not covered here, would be to provide python runtime for the ML artifacts, say via BTP Cloud Foundry or Kyma.
To enable seamless continuous development here are the key steps that describe a typical flow.
The Auto-generation capabilities make the handshake very convenient while ensuring both sides of the development continue to work in their naturally preferred environment.

Data Scientist - CAP Developer Handshake
In the example here we will use SAP Business Application Studio (BAS) as the development IDE for both the python runtime, typically done by a Data Scientist role and the Full-Stack Cloud Application Development done by CAP developer.
1. Build ML Model with Jupyter Notebooks in BAS
Note: It is not mandatory to use BAS for the python development to use the auto-generation functionality. The Data Scientist is free to use the IDE of their choice where they develop the HANA ML models. It is suggested here if the Data Scientist and CAP developer prefer to have similar IDE for developing.
Business Application Studio now has support for Jupyter Notebooks and these extensions can easily be installed in your BAS Workspace.
For Data Science developer if they are only interested in having Jupyter Notebook support and python runtime they can just create a Basic Dev Space and add Python Extension
Python Extension in Business Application Studio
With this extension the ipkernel gets automatically installed when you create a python notebook and we no longer need to install it separately (as was required before, prior to the development extension in Business Application Studio).
Create Python Environment
To ensure all installations are saved in the App Studio workspace we need to create a python environment and install all required packages in the environment. This is anyways best practice when installing python packages and creating dedicated environments as needed.
This can be done by opening a terminal in App Studio with the following command
python3 -m venv <name of your env>Now we can create a new Python notebook with the Create New Jupyter Notebook command or import existing notebooks in the workspace.

Create Python Jupyter Notebook with Command Palette
Select the kernel created via the step above when you created your python environment.
Now all packages installed in the env will be there in the workspace even after the workspace stops and restarts. If you install the packages in the notebook choose the environment when prompted to choose the kernel like below (env in example here)

Choose Python Kernel created before
or if installing via the terminal activate the environment in the terminal with activate and then install packages
source bin/activate
Activate Kernel in the Terminal
Now we can use Jupyter Notebooks as usual

Data Analysis with HANA ML

Model Building
2. Generating the CAP Artifacts from HANA
HANA ML Python Client API has been providing strong capabilities for python developers who can benefit from using the more convenient python interface when interacting and creating ML models in SAP HANA. For details on this refer to Yannick Schaper's blogpost and blogpost from christoph.morgen Updates for the Data Scientist Building SAP HANA embedded machine learning scenarios.
With the latest release of HANA ML these capabilities are take one step further to ease the incorporation of ML assets into the project development for CAP.
I will show 2 use-cases where the generator adapts and creates the appropriate set of artifacts. In general the capabilities are available all PAL and APL ML algorithms.
1. Example Prophet Algorithm with Additive Model Forecast
For a detailed discussion on the use-case and related datasets refer to this excellent blogpost from frank.gottfried Develop a machine learning application on SAP BTP Data Science part
This is the main code snippet the Data Scientist uses in python to train and then infer using the trained model.
import hana_ml
from hana_ml import dataframe
from hana_ml.algorithms.pal.tsa.additive_model_forecast import AdditiveModelForecast
from hana_ml.algorithms.pal.tsa.additive_model_forecast import AdditiveModelForecast
amf = AdditiveModelForecast(massive=True,growth='linear',
changepoint_prior_scale=0.06,
weekly_seasonality='True',
daily_seasonality='True'
)
## Model Training
amf.fit(data=train_rnk_hdf, key="PRICE_AT_TIMESTAMP", group_key="STATION_UUID", holiday=holiday_data_hdf)
## Model Inference
result = amf.predict(data=test_rnk_hdf, key="PRICE_AT_TIMESTAMP", group_key="STATION_UUID")Now to generate the corresponding HANA artifacts which can be passed to the CAP developer for the corresponding project the python developer calls the following after the above steps, once they are satisfied with the model quality and ready to hand over for consumption in the application.
from hana_ml.artifacts.generators import hana
from hana_ml.artifacts.generators.hana import HANAGeneratorForCAP
hanagen = HANAGeneratorForCAP(project_name="PAL_PROPHET_FORECAST_4CAP",
output_dir=".",
namespace="hana.ml")
hanagen.generate_artifacts(amf, model_position=True, cds_gen=False,tudf=True)For complete reference to the HANAGeneratorForCAP refer to the the documentation hana-ml documentation
For the example of Prophet Algorithm with Additive Model Forecast(AMF) this is the content that gets generated by HANAGeneratorForCAP.generate_artifacts()

Auto-generated Artifacts
The content above has the following HANA ML artifacts required for CAP framework. It prefixes the content by <namespace> provided by the user "hana.ml" in example above and then specifics based on the ML model pal-massive-additive-model here.
- Stored procedures for training and prediction. For each there is a *base* procedure and a *cons* procedure. The *cons* procedures are the procedure for end consumption used for calling the training and the inference in the target system. So for above example the stored procedure
hana_ml_cons_pal_massive_additive_model_analysis
is to be called to create the ML training model.
Subsequently
hana_ml_cons_pal_massive_additive_model_predict is to be called for getting the predictions from the model at the time of inference.
The *base* procedures are required by the HDI module and called via the corresponding *cons* procedure.
if tudf = True is used by the HANAGeneratorForCAP.generate_artifacts(), then it also generates a User-defined Table Function for inferencing the ML model. This is helpful for cases where one does not need to persist the inference results but have them generated on the fly. Alternatively use the apply/predict stored procedure (which is generated by default in the above step).
For the training step this option is not feasible as during training the model needs to be persisted and cannot be supported by a table function call only.
- The required synonyms that are needed for accessing the catalog tables/views the Data Scientist used for modeling
- The grants required by HDI module for the HDI runtime user
- CDS DB Entities within the namespace provided before "hana.ml" in my example for procedures and for CDS to generate the required hdbtables and hdbviews.
 Auto-generated backend CDS (hana-ml-cds-hana-ml-base-pal-massive-additive-model-analysis.cds)
Auto-generated backend CDS (hana-ml-cds-hana-ml-base-pal-massive-additive-model-analysis.cds) - CAP CDS Catalog Service definition for providing OData endpoints to the ML artifacts. For our example we get the following which is needed to create the OData endpoints for generated artifacts.

Auto-generated Node.js Catalog Service (hana-ml-cat-service.cds)
The number of entities depend on the ML model used. For my example the first 2 entities are the Trained Model and any errors incase generated during training.
The next 3 entities provide access to the 3 outputs from running the Prediction as described in SAP Documentation of AMF

The last entity in my example here HanaMlApplyFuncPalMassiveAdditiveModelPredict is the corresponding endpoint which is generated with tudf = True flag as described above.
2. Example : Unified Classification
In this case lets say the user performs Classification via PAL Unified Classification.
This code snippet for example performs the fit and predict function on hana ml dataframes.
import hana_ml
import hana_ml.dataframe as dataframe
from hana_ml.algorithms.pal.unified_classification import UnifiedClassification
connection_context = dataframe.ConnectionContext(
url, int(port), user)
## These help reviewing the sql trace
conn.sql_tracer.enable_sql_trace(True)
conn.sql_tracer.enable_trace_history(True)
df_train_valid = connection_context.table(training_valid_tbl,schema=connection_context.get_current_schema())
df_test = connection_context.table(test_tbl,schema=connection_context.get_current_schema())
rfc_params = dict(n_estimators=5, split_threshold=0, max_depth=10)
rfc = UnifiedClassification(func="RandomForest", **rfc_params)
rfc.fit(df_train_valid,
key='ID',
label='CLASS',
categorical_variable=['CLASS'])
cm = rfc.confusion_matrix_.collect()
rfc.predict(df_test.drop(cols=['CLASS']), key="ID")To generate the HDI artifacts for CAP its same step as before except now we use the ML model for Unified Classification
from hana_ml.artifacts.generators import hana
from hana_ml.artifacts.generators.hana import HANAGeneratorForCAP
hanagen = HANAGeneratorForCAP(project_name="PAL_UC_4CAP",
output_dir=".",
namespace="hana.ml")
hanagen.generate_artifacts(rfc, model_position=True, cds_gen=False,tudf=True)In this case we get the same *base* and *cons* procedures and grants and synonyms (pointing to the appropriate catalog tables used by the Data Scientist, and access to _SYS_AFL) as before. However the CDS entities that are required and get generated depends on the ML model that was used.
In our example here the Massive Additive Model produces 1 output table besides the model table. The Unified Classification Model on the other hand produces 7 output tables besides the model table.

PAL Unified Classification Training
The HANAGeneratorForCAP automatically generates the right entities in the appropriate context Fit and Predict with the appropriate number of outputs and corresponding signatures. The alleviates the need for the CAP developer to code these by hand.

Comparing CDS Entries for different ML models
I showed the second ML usecase only to highlight how the generator adapts based on your chosen ML model. For the rest of the flow I will use usecase 1 with Prophet algorithm of PAL_MASSIVE_ADDITIVE_MODEL.
Sharing the generated artifacts
The Data Scientist developer can share the generated artifacts as a zip or the recommended approach would be to share the artifacts via a git repository to ensure continuous development.
3. Develop CAP Project for Full Stack Application with HANA ML
Incorporating the generated artifacts in a CAP Project
Now we switch to what the CAP developer needs to do. Typically they would already have a CAP project for the application. For details on how to start with such an application refer to to this Tutorial : HANA Cloud Project with CAP and blog on CAP with HANA Cloud
In Business Application Studio you would have a Full Stack Cloud Application workspace (instead of Basic as used by Data Scientist in 2. above) and you have a CAP Project as described in the tutorial above.
The CAP developer needs to bring in the generated artifacts above into this project. Either these are provided as zip files or through git. If they are a zip file the developer can use the Upload functionality to bring these files to BAS Workspace or ideally they are in git repo and developer pulls the files in BAS through the Get Started Command Pallet or directly in the terminal.
Get CAP files from git repo
Once the files are there they need to be added in the right structure in the target CAP project. Since we created a project from CAP Project template it would have the following folder structure
- app
- db
- src
- srv
The generated files from the Data Scientist git repo also has the same structure and we need to copy over all the files with the <namespace> prefix into the target project within the same folder structure.

The project can have other files and files generated by the framework for example .hdiconfig and undeploy.json etc. The project would already have its package.json and check it has the hana-cloud in the cds requires as described in step 5.4 of the Tutorial : HANA Cloud Project with CAP.
Providing Access and Privileges for CAP
1. User Provided Service for PAL/APL privileges
When developing in python the HANA Cloud user would have had the right privileges below
- AFL__SYS_AFL_AFLPAL_EXECUTE_WITH_GRANT_OPTION
- AFL__SYS_AFL_APL_AREA_EXECUTE
For CAP project we would need the same privileges for the HDI runtime user that will get generated. These are provided through User Provided Services as described in Step 1 of Wei Han's blogpost
or one can easily create the service through Business Application Studio by adding a Database connection as shown below

Creation of User Provided Service in BAS

Added User Provided Service with DB user with right privileges
The provided hdbgrants file assumes that the DB user used by the Data Scientist is the same that will be used in CAP. If this is the case then use the same DB user, who already would have the privileges for calling PAL and APL and required catalog objects when creating the service above. If the user needs to be different in the CAP application, as this could be a different HANA tenant which will have the same data as required by the Data Scientist then you would need to edit the auto-generated hdbgrants file db/src to reflect the user for CAP.
2. Bind the User Provided Service
Now that you have the User Provided Service, its needs to be bound to the CAP Project. This can be done by using the binding functionality in BAS under SAP HANA Projects (this in turn modifies the mta.yaml file appropriately). Here you need to use the Existing user-provided service instance when adding the service instance and use the service created in Step 1 above.
Alternatively this can be done by editing the mta.yaml directly, for reference the mta.yaml needs reference to cross-container service with the service name added in Step 1
- name: ml_hana_demo-db-deployer
type: hdb
path: db #gen/db
requires:
- name: ml_hana_demo-db
properties:
TARGET_CONTAINER: ~{hdi-service-name}
- name: cross-container-service-1
group: SERVICE_REPLACEMENTS
properties:
key: ServiceName_1 # Check this name is the same in the provided hdbgrants file otherwise modify appropriately as they need to match
service: ~{the-service-name}
parameters:
buildpack: nodejs_buildpack
resources:
- name: cross-container-service-1
type: org.cloudfoundry.existing-service
parameters:
service-name: ml_hana_bas_ups # Name of User Provided Service created in Step 1
properties:
the-service-name: ${service-name}
By default if this is the first cross-container service being added to the project then it would have a name cross-container-service-1 and key ServiceName_1. This key is used by the hdbgrants file to match the right service. If the name is different from ServiceName_1 then modify the hdbgrants file to match the key here.
Build and Deploy the application
Now that we have the artifacts in place, we are ready to create the mtar and deploy it to CF Space.
For this follow the usual process either by right clicking on the mta.yaml and triggering a build or call mbt build via the commandline. Ensure you have already called npm install to have all required modules in your workspace.
Optionally, as always you can also first test the HDB deploy only by deploying the db module via SAP HANA Projects deploy in BAS

HDB Dev-Test Deploy
When you trigger the build CAP framework will additionally generate the required hdbtables etc as described in the autogenerate cds file, so the required artifacts come from the cds definitions provides in cds without the need of manual coding
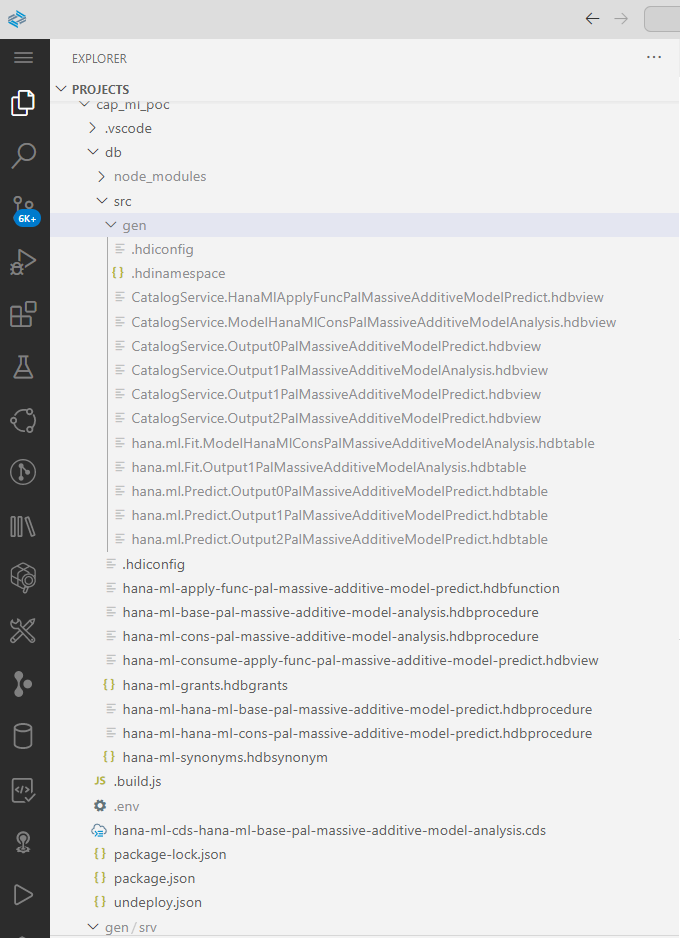
CDS Generated Artifacts
Once the build is successful we are ready to deploy the mtar created in mta_archives. You can right click on the archive and deploy or use commandline to deploy for example with
cf deploy mta_archives/<project_name_version-name>.mtar --retries 1Call the ML Training procedure
Once we have all the artifacts deployed in the HDI container, we still need to call the ML training procedure provided by <namespace>-cons-<ml model>.hdbprocedure (in the example above hana_ml_cons_pal_massive_additive_model_analysis.procedure), otherwise the endpoints will return no data. The procedure can be triggered via SQL Console on DB Explorer of the deploy HDI container.
Typically you would also want the application (and or model monitoring framework) to have an OData Endpoint to trigger the training call.
For this you would need to the Node.js wrapper on the srv side to enable this functionality.
Add the following to the hana-ml-cat-service.cds
/*** Add functions to call the Model Training */
function Model_Train() returns Boolean;
/** The Predict can be called via OData endpoint or as a stored procedure for persisting data */
function Prices_Predict() returns Boolean; Add corresponding Node.js handler custom code for the functions added above
const cds = require('@sap/cds')
/***
**** Add Node.js Function Handlers for Training and Predict functions
****/
module.exports = cds.service.impl(function () {
this.on('Prices_Predict', async () => {
try {
const dbClass = require("sap-hdb-promisfied")
let db = new dbClass(await dbClass.createConnectionFromEnv())
let dbProcQuery = "CALL HANA_ML_CONS_PAL_MASSIVE_ADDITIVE_MODEL_PREDICT(OUT_0_HANA_ML_CONS_PAL_MASSIVE_ADDITIVE_MODEL_PREDICT => ?,OUT_1_HANA_ML_CONS_PAL_MASSIVE_ADDITIVE_MODEL_PREDICT => ?,OUT_2_HANA_ML_CONS_PAL_MASSIVE_ADDITIVE_MODEL_PREDICT => ?)"
console.log("------Before running db procedure--------")
let result = await db.execSQL(dbProcQuery)
console.log("------After running db procedure--------")
console.table(result)
return true
} catch (error) {
console.error(error)
return false
}
})
this.on('Model_Train', async () => {
try {
const dbClass = require("sap-hdb-promisfied")
let db = new dbClass(await dbClass.createConnectionFromEnv())
let dbProcQuery = "CALL HANA_ML_CONS_PAL_MASSIVE_ADDITIVE_MODEL_ANALYSIS(OUT_0_HANA_ML_CONS_PAL_MASSIVE_ADDITIVE_MODEL_ANALYSIS => ?,OUT_1_HANA_ML_CONS_PAL_MASSIVE_ADDITIVE_MODEL_ANALYSIS => ?)"
console.log("------Before running db procedure--------")
let result = await db.execSQL(dbProcQuery)
console.log("------After running db procedure--------")
console.table(result)
return true
} catch (error) {
console.error(error)
return false
}
})
})This requires the module sap-hdb-promisfied. To enable this either call npm install or add the following to the dependencies in the package.json file
Since the training procedure needs to persist the model to the DB it is not possible to provide this functionality as a user provided function call. For predict this option is available if you had tudf = true when calling the HANAGeneratorForCAP.generate_artifacts() as described in section 2 above.
The framework also enables the creation of Fiori views automatically for data exposed via OData endpoints. To enable this ensure the package.json file has fiori_preview enabled. Here is a sample package.json, the exact versions will keep evolving and may not match yours but the overall structure would remain similar as below
{
"name": "cap_ml_poc",
"version": "1.0.0",
"description": "A simple CAP project.",
"repository": "<Add your repository here>",
"license": "UNLICENSED",
"private": true,
"dependencies": {
"@sap/cds": "^6",
"@sap/cds-odata-v2-adapter-proxy": "^1.9.21",
"express": "^4",
"hdb": "^0.19.0",
"sap-hdb-promisfied": "^2.202304.2"
},
"devDependencies": {
"@sap/ux-specification": "^1.108.6",
"rimraf": "^3.0.2",
"sqlite3": "^5"
},
"scripts": {
"start": "cds-serve"
},
"cds": {
"build": {
"tasks": [
{
"for": "hana",
"dest": "../db"
},
{
"for": "node-cf"
}
]
},
"requires": {
"db": {
"kind": "hana-cloud"
}
},
"features": {
"fiori_preview": true
}
}
}
Once you added the above modifications you will need to rebuild and redeploy.
If you make no changes to data sources, the above application will use the very same data sources used by the Data Scientist during model development. They would typically have used HANA Catalog tables, the very same are used by default by the generated procedures and the hdbsynonym file ensure these are available in the HDI container. This works if the Data Scientist and the CAP application is being developed on the same tenant. If this is not the case, the CAP developer would need to modify the generated code to reflect the names of the data sources from the Catalog schema, ensure the cross-container-service is created for a user which has access to this Catalog and the tables (views) have the exact same data definition as used by the Data Scientist during training.
4. Consume ML artifacts in Full-Stack Application
Once the deployment is successful you can go to the BTP cockpit and find the application in the target space of your project under Applications
Clicking the link should give you a page which looks like this, this has the OData endpoints for artifacts created automatically for the project.

Service Endpoints
To call the endpoint for Training you need to add /catalog/Model_Train() to your service url().
Once training is done the inference call be called to get predictions. For example if you call the HanaMLApplyFuncPalMassiveAdditiveModelPredict endpoint above, the following predictions are generated on the fly and viewable with Fiori preview.

Now that we have the db and srv endpoints in place, we can add the UI app to the project or alternatively pass on the required endpoints to the UI developer to incorporate in the frontend.
Developing the frontend to ensure the best UX which as we know is an art and craft of its own, which I will not cover here. However to jumpstart a UI you can use the Fiori Template Wizard from BAS by opening the Command Palette

BAS Command Palette
Search for Fiori Open Application Generator to get a Template Wizard to help initiate the UI part of the app

BAS Template Wizard
Conclusion
The intent of this blogpost is to walkthrough an end-to-end ML model development and how a Data Science developer can work in close collaboration with the CAP developer while each developer can stay in their natural environment while ensuring continuous development can occur effectively. It is heavily build on work previously done, and might turn out to be a longer read than previously intended but I wanted to put all the pieces in one place to facilitate incase you are venturing this space for the first time.
Sometimes with auto-generation the line between what gets generated, what the coder needs to develop gets a bit hazy especially if you start from an example codebase. I wanted to unravel the power of generation capabilities provided by hana-ml artifacts.generators, CDS/CAP generators to make efficient use of the out-of-the box capabilities provided by the framework so the developers can focus only the custom code needed based on their requirements.
Hope you find it useful when building your Intelligent Data Apps on BTP.
The complete codebase for the ML app would be available here SAP-samples Git Repo.
This work would not been possible without the tremendous help from christoph.morgen, raymond.yao, frank.gottfried and aferreirinha Thank you all!
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
 Bluesky
Bluesky- Built an MCP Server for SAP Cloud Integration in Technology Blog Posts by Members
- API-Centric Integration on SAP Integration Suite – Part 1: Build and Deploy Your API in Technology Blog Posts by SAP
- Joule A2A: Async Push Notifications for Long-Running Agents in Technology Blog Posts by SAP
- From Hype to Hands-On: Level Up Your AI Skills This May in Technology Blog Posts by SAP
- Improving RAG Retrieval with Cohere Rerank on SAP AI Launchpad in Technology Blog Posts by SAP
| User | Count |
|---|---|
| 74 | |
| 60 | |
| 40 | |
| 37 | |
| 33 | |
| 28 | |
| 27 | |
| 23 | |
| 23 | |
| 22 |