
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Datasphere Replication Flows Blog Series Part ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Associate
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-04-2023
3:02 PM
This blog is part of a blog series from SAP Datasphere product management with the focus on the Replication Flow capabilities of SAP Datasphere:
In the first two blogs, you learned about Replication Flows in SAP Datasphere and the concept of premium outbound integration. In this blog, we will describe the upcoming Kafka and Confluent integration with Replication Flows in SAP Datasphere.
Here is the table of contents for this blog.
- Introduction
- Confluent
- Kafka in SAP Datasphere Replication Flows
- Roadmap Outlook
I want to take the opportunity to express my gratitute to our colleagues from Confluent for providing the content of section two of this Blog and for the support in general through the creation of this Blog. I would also like to say thank you to katryn.cheng, tobias.koebler and Kevin Poskitt from SAP for their various contributions to the Blog.
1. Introduction
Many organizations have turned to real-time data streaming platforms to help accelerate their business transformation, enhance their digital customer experience, and deliver real-time analytics. At the forefront of many of these initiatives is open-source Apache Kafka®, used today by more than 80% of the Fortune 100.
Earlier this year we announced several leading technology partners for SAP Datasphere including Confluent, a pioneer and leader in enterprise data streaming founded by the original creators of Kafka. SAP and Confluent will make it easier for customers to connect SAP data to external data in real time, enabling them to react faster and unlock use cases that will help them transform their business.
The goal of integrating SAP Datasphere with data streaming technology like Kafka and Confluent, is to enable real-time data to value scenarios with SAP data and provide end-to-end capabilities powered by SAP Datasphere. In this blog, you will see how the new Kafka integration with SAP Datasphere simplifies the streaming of data from systems like SAP S/4HANA to external applications and systems.
2. Confluent
Since its original creation by Confluent’s founders in 2011, Apache Kafka has become one of the most popular open source projects globally and the de facto standard for real-time data streaming. However, realizing value from self-managed Kafka can be an expensive, multi-year journey requiring significant investment and deep technical expertise. Only Confluent provides a fully managed data streaming platform that is cloud-native, complete, and available everywhere it’s needed—one that eliminates the operational challenges of Kafka and allows teams to fully focus on innovating with real-time data.
- Cloud Native: Confluent customers spend more time building value when working with a Kafka service built for the cloud and powered by the Kora Engine including GBps+ elastic scaling, infinite storage, a 99.99% uptime SLA, multi-AZ clusters, no-touch Kafka patches, highly predictable/low latency performance, and more—all while lowering the total cost of ownership (TCO) for Kafka by up to 60%.
- Complete: With Confluent, you can deploy new use cases quickly, securely, and reliably when working with a complete data streaming platform with 120+ connectors (70+ provided fully managed), built-in stream processing with serverless Apache Flink (preview), enterprise-grade security controls, the industry’s only fully managed governance suite for Kafka, pre-built monitoring options, and more.
- Everywhere: Maintain deployment flexibility whether running in the cloud, multicloud, on-premises, or a hybrid setup. Confluent is available wherever your applications reside with clusters that sync in real time across environments to create a globally consistent central nervous system of real-time data to fuel the business.
Confluent’s data streaming platform is highly versatile, unlocking unlimited use cases dependent upon streaming data. When ERP data from SAP is merged with non-SAP sources in real time, the highest impact use cases come to life. For example, pipelines to power real-time sales performance analytics and optimization for retailers built on Confluent Cloud by combining transaction details from SAP together with e-commerce campaign data and customer click streams. Additionally, an auto parts manufacturer can reduce warranty costs and increase customer satisfaction rates by performing real-time analysis of customer order details together with data streams from supply-side IoT devices and manufacturing execution systems.
If you’re interested in learning more, check out Confluent’s Flink SQL Workshop (GitHub) about building real-time stream processing pipelines with multiple data sources.
2. Kafka as target for SAP Datasphere Replication Flows
In this section, we will describe the Kafka related features planned with the 2023.25 and 2024.01 release of SAP Datasphere and details on how to use them. With these releases, Kafka will be supported as a target for Replication Flows.
Kafka as a new Connection Type in SAP Datasphere
In the connection management area of an SAP Datasphere space, it is now possible to select Kafka as a connection type in the connection creation wizard. This connection type offers connectivity to a generic Kafka cluster independent of whether it is a self-hosted or a managed Kafka offering.
 Here are the different configuration options for Kafka.
Here are the different configuration options for Kafka.
Kafka Brokers
A comma-separated list of Kafka brokers in the format <host>:<port>.
Cloud Connector
This setting configures whether a Cloud Connector is used if the source is an on-premise Kafka cluster.
Authentication
The following SASL based authentication methods are supported.
| Authentication Type | SASL Authentication Type | Properties |
| No Authentication | n/a | |
| User Name and Password | PLAIN | Kafka SASL User Name* Kafka SASL Password* |
| Salted Challenge Response Authentication Mechanism (256) | SCRAM256 | Kafka SASL User Name* Kafka SASL Password* |
| Salted Challenge Response Authentication Mechanism (512) | SCRAM 512 | Kafka SASL User Name* Kafka SASL Password* |
| Kerberos with User Name and Password | GSSAPI | Kafka Kerberos Service Name* Kafka Kerberos Realm* Kafka Kerberos Config* User Name* Password* |
| Kerberos with Keytab File | GSSAPI | Kafka Kerberos Service Name* Kafka Kerberos Realm* Kafka Kerberos Config* User Name* Keytab File* |
*mandatory
Security
We support Transport Layer Security (TLS) settings for encryption as well as server and client certification.

| Option | Values | Explanation |
| Use TLS | true or false | Choose whether to use TLS encryption or not. |
| Validate Server Certificate | true or false | Choose whether to use a Certificate Authority for the Server Certificate or not. Only visible if Use TLS is set to true. |
| Use mTLS | true or false | Choose whether to use mutual TLS or not. In this case a Client Key and Client Certificate need to be provided. Only visible if Use TLS is set to true. |
Remark: In case Validate Server Certificate is set to true, a corresponding TLS certificate needs to be uploaded via the SAP Datasphere System Configuration.

Kafka as a new target for Replication Flows
In Part 2 of this blog series on premium outbound integration, we used SAP S/4HANA as the source so we will use it again to show an end-to-end replication scenario with Kafka as a target.
For the step-by-step guide, we will assume that we have a SAP Datasphere tenant running with a space that is ready to use.
For our target, we will use a Confluent Cloud managed Kafka Cluster and use SASL PLAIN as authentication mechanism with API Key and Secret.
Creating a new Kafka connection to Confluent Cloud
First, we’ll create a generic Kafka Connection in the connection management of SAP Datasphere by choosing the corresponding connection tile.

Remark: To provide deeper integration with our partner Confluent, we will add a dedicated connection type for Confluent in the first quarter of 2024. This new connection type will be tailored to the additional and specific capabilities offered by Confluent Cloud and Confluent Platform. See roadmap for details.
Creating a Replication Flow
Let's assume that we want to replicate the following CDS views from our SAP S/4HANA system.
- Z_CDS_EPM_BUPA
- Z_CDS_EPM_PD
- Z_CDS_EPM_SO
We can create a Replication Flow via the SAP Datasphere Data Builder and choose SAP S/4HANA as the source system with CDS as the Container.

Now, we can easily browse through the available CDS views to find the one we need, and select Z_CDS_EPM_BUPA, Z_CDS_EPM_PD and Z_CDS_EPM_SO.
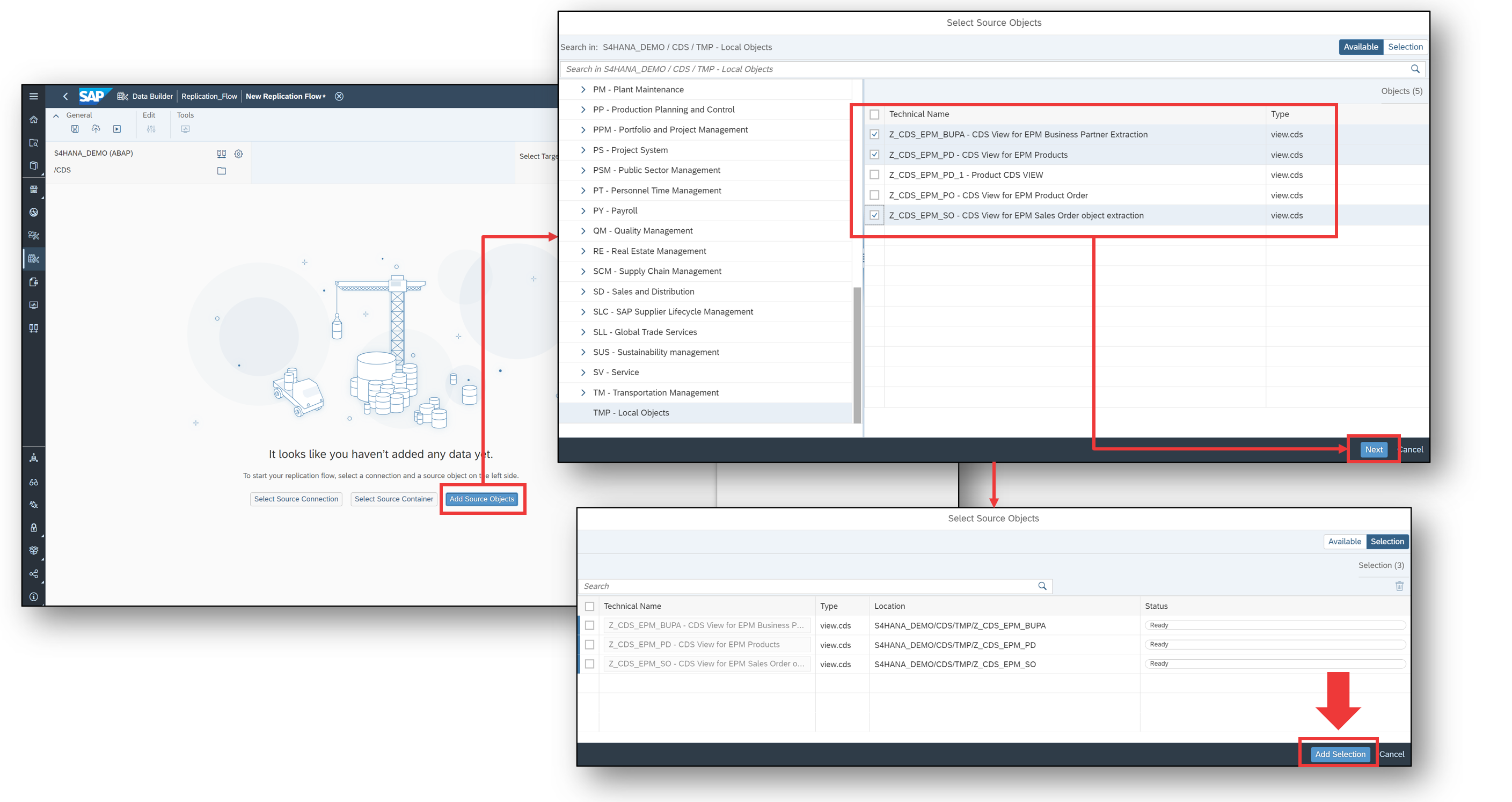
Three tasks are then generated automatically and we can now choose the Confluent Cloud connection as the target.

We do not need to specify a target container in the Replication Flow user interface as it was the case for the source connection to SAP S4/HANA (e.g. CDS) since for Kafka there exists no superordinate container layer concept. Instead we have a direct mapping between the source CDS views and corresponding target Kafka topics.
A new Kafka topic is created for every source CDS view so for each of the three source CDS views, their targets are automatically displayed and will correspond to separate Kafka topics. We have the ability to rename the new target Kafka topics so let’s remove the Z_CDS_ prefixes.

The target Kafka topics are named as displayed in the following figure.
 It is also possible to use existing Kafka topics as targets, however keep in mind that schema registry is currently not supported but planned for Q1 2024.
It is also possible to use existing Kafka topics as targets, however keep in mind that schema registry is currently not supported but planned for Q1 2024.
As Load Type for each task, we will choose Initial and Delta.

For the target, we can configure settings globally on the Replication Flow level, or configure individually at the task level. We will set the Replication Factor to 3 globally and keep everything else as is.

Remark: In case an existing Kafka topic is used as a target, a Truncate flag can be set for such a target topic at the task level. Note that setting this flag enforces a re-creation of the topic before the replication starts.
The following table contains a description of the available settings.
| Setting | Value | Explanation |
| Replication Thread Limit | Number | The number of parallel replication threads that can be executed during the replication process. Only available in Global configuration. |
| Number of Partitions | Number | The number of Kafka Partitions for the target Kafka topic. Only used for new topics that don’t yet exist in the Kafka Cluster, otherwise the setting is ignored. |
| Replication Factor | Number | The Kafka replication factor for the Kafka topic. Only used for new topics that don’t yet exist in the Kafka Cluster, otherwise the setting is ignored. |
| Message Encoder | AVRO or JSON | The message format for the Kafka topic. |
| Message Compression | No Compression Gzip Snappy LZ4 Zstandard | The compression method for the Kafka messages that are sent to a Kafka topic. |
| Overwrite Target Settings at Object Level | true or false | True: The global configuration overwrites the configurations made at task level. Only available in global configuration |
Remark: Schema registry is not in scope for the generic Kafka integration described in this blog. Confluent schema registry will be supported with the dedicated Confluent connection type (see roadmap outlook in section 4).
Deploy and run the Data Replication
Next, we save, deploy, and run the Replication Flow.

This will start the replication process and can be monitored in the monitoring environment of SAP Datasphere. After the initial load has finished each replication task will stay in Status Retrying to wait for changes in the corresponding source CDS view.

Finally, let’s navigate to the target Confluent Cloud environment and have a look at the moved data.

In the next section, we will share new integrations tailored for Confluent and planned for the first half of 2024.
4. Roadmap Outlook
To provide a more comprehensive integration with the managed Kafka offering of our open data partner, Confluent, we are delivering features that will make it easy for customers to combine data from Confluent and SAP Datasphere. The following list of improvements is planned to be released in the first half of 2024.
Dedicated connection Type for Confluent (Q1 2024)
In addition to the Kafka connection type mentioned above, there will be a dedicated connection type for Confluent tailored to the strengths of both Confluent Cloud and Confluent Platform. This connection type allows the specification of the Confluent managed schema registry. The different settings and authentication mechanisms for Confluent Cloud and Confluent Platform can also be specified. Support for the following authentication mechanisms are planned with this release.
| Confluent offering | Authentication Mechanisms |
| Confluent Cloud |
|
| Confluent Platform |
|
We are going to support Transport Layer Security (TLS) settings for encryption as well as server and client certification with the same scope that was described earlier in this blog for the generic Kafka connection type.
Integration with Confluent Schema Registry for Confluent as a target for Replication Flows (Q1 2024)
For the Confluent connection type, we will support schema registry for scenarios where Confluent is the target for Replication Flows. Both Confluent Cloud and Confluent Platform are planned to be supported with this new Confluent connection type. See it in the roadmap.
Support Confluent as a source for Replication Flows (Q2/Q3 2024)
For the consumption of data within SAP Datasphere coming from Confluent, we will support Confluent as a source for Replication Flows. These new features will allow customers to replicate data from Confluent Kafka topics into SAP Datasphere. This release will allow basic adjustments to the target SAP Datasphere structure based on a chosen source Kafka topic and schema. See it in the roadmap.
Summary
In this Blog you learned about the new Kafka integration in SAP Datasphere. The intention was to provide as many details as possible and provide a step-by-step guide how to setup a running SAP Datasphere to Kafka scenario.
In case you are interested in further material how Kafka can be leveraged with SAP Datasphere, checkout the following opportunity.
Join us and see it in action
Ready to jump in and see how SAP Datasphere and Confluent Cloud work together? Join Confluent and SAP on December 12th, 2023 for our demo webinar, “Build Real-time Customer Experiences with SAP Datasphere and Cloud-Native Apache Kafka®”.
Visit Confluent Cloud on the SAP® Store and start your free trial of Confluent Cloud today. New signups receive $400 to spend during their first 30 days. No credit card required.
- SAP Managed Tags:
- SAP Datasphere,
- Data and Analytics,
- SAP S/4HANA,
- Partnership,
- SAP S/4HANA Public Cloud,
- SAP Business Technology Platform
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
107 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
72 -
Expert
1 -
Expert Insights
177 -
Expert Insights
344 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
386 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,872 -
Technology Updates
476 -
Workload Fluctuations
1
Related Content
- What’s New in SAP Datasphere Version 2024.10 — May 7, 2024 in Technology Blogs by Members
- Replicate BOM Product from S/4 Hana Private Cloud to CPQ 2.0 in Technology Q&A
- Tracking HANA Machine Learning experiments with MLflow: A conceptual guide for MLOps in Technology Blogs by SAP
- Tracking HANA Machine Learning experiments with MLflow: A technical Deep Dive in Technology Blogs by SAP
- Replication Flow Blog Part 6 – Confluent as Replication Target in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 17 | |
| 15 | |
| 13 | |
| 10 | |
| 9 | |
| 7 | |
| 7 | |
| 7 | |
| 7 | |
| 6 |