- SAP Community
- Products and Technology
- Technology
- Technology Q&A
- Aggregation functions not providing expected resul...
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Aggregation functions not providing expected results in claculation view
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 04-19-2017 1:22 PM
Hi Experts,
Need your expertise to clear my doubts regarding aggregation node in calculation view .
I have a dataset which is at item level .Need to get the unique records from it by aggregating the base records. Need to get the count of some intermediate attribute and then find MAX of the count of the intermediate value. This needs to be done at 3 steps.
1. Aggregate the base set by selecting only those records which are required for next level.



2. Out the records obtained in step 1 create a calculated column to obtain to obtain an attribute and then find the number of times (count )the attribute appears in the dataset obtained in step1 .


3.Use the result set obtained in step 2 to find the record whose count (obtained in previous step)values is MAX


The issue is I am able to obtain the proper aggregation in step 1 and count in step 2 but when I perform max operation of the count value in a second calculation view , the view returns sum of count
The step by step screenshot along with the result of that node is attached.

Can you please comment if the output appearing as shown in step 3 is correct and what i am expecting (attached in the screenshot ) needs to be obtained by some other means .
The DB version is
1.00.122.07.1486663129
Studio Version: 2.3.13
Best Regards
Rohit
- SAP Managed Tags:
- SAP HANA studio,
- BW SAP HANA Modeling Tools (Eclipse)
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi Rohit,
1. Generate a dummy calculated column below rank block that is equal to 'A' (CHAR 1)
2. Use rank, order by count descending, group by dummy
3. Set threshold (fixed) to 1

Example tutorial:
https://www.youtube.com/watch?v=yA3qaTVSFVg
Regards,
Mateusz.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Thanks a lot Mateusz :),
I am now able to get the MAX of CC_COUNT using the Rank technique you just suggested . But I still have few questions
1. When I tried to see the visualize plan for the projection1 for second CV , I see that all the columns which there in generating the DISTINCT COUNTER of first CV is present (even though the column AUGDT and FAEDN is hidden ). I am asking this because if I dont choose to use a Rank node node and use a MAX , MIN function provided in the aggregation node it should work as well but strangely it isnt .
2. Another question is related to distinct counters
in the first cv output of aggregation 1 is
If I select MANDT , GPART , VKONT,sum(BETRW), sum(CC_FREQ) the out put should be
But instead the result of sum(CC_FREQ) is 1 for the entire data set .

I am asking this because I dont want to use a counter , instead I want to use a aggregated column to do the work .
3. Regarding the concept of Transparent filter :- Any column which takes part in the distinct counter calculation cannot be set as transparent filter, even though it has been hidden in the semantics after counter calculation .But if I dont want that hidden attribute to take part in further aggregation if the base calculation view is called from a different view.
Can you please throw some light on these as well so that I can have correct understanding of these features .
Thanks once again .
Best Regards
Rohit
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi,
I feel like I'm misinterpreting something, but here is what I think:
1. Aggregation in graphical calculation view are grouped by everything that is in the output but it is not aggregated (be sure that measures are aggregated and they are not in output as characteristics). Check SQL group by for more information. For every characteristic (that is used in group by) is equal then the aggregation
2. What do you have in group by? The screen from output tab would be great.
3. Check the blog linked below
https://blogs.sap.com/2015/10/26/getting-the-counters-right-with-stacked-calculation-views/
Regards,
Mateusz.
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi Mateusz,
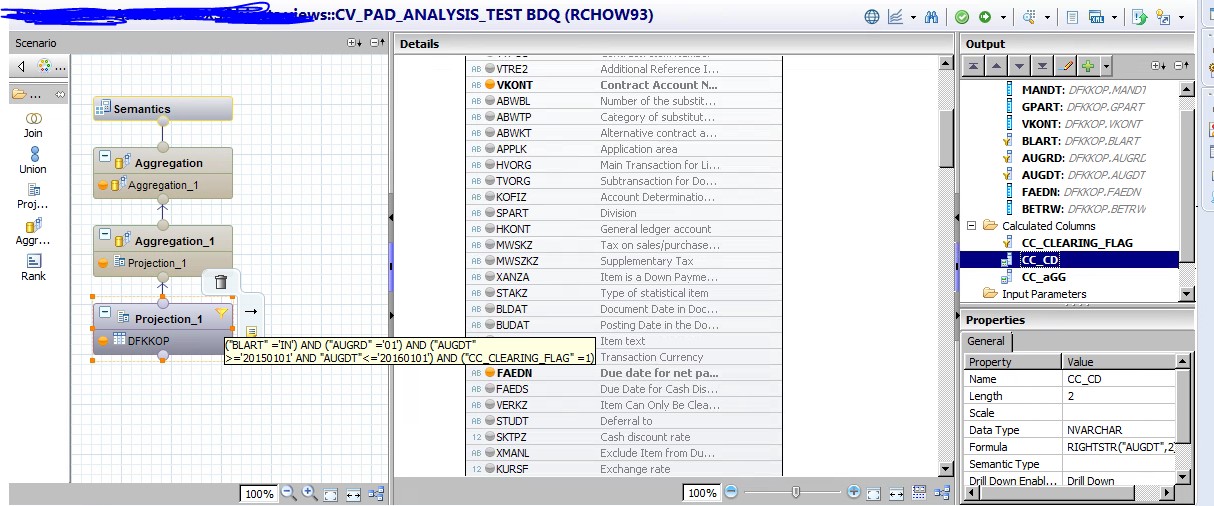
That was also my understanding that in aggregation the measure is aggregated on basis of the attribute columns which are in the o/p of that node (be it semantics or intermediate node ) . But with this current data set its not behaving the same .
For example consider the dtable ata set which has been obtained after single level of aggregating an item table along which some filters on AUGDT and FAEDN column .
 inputdata.jpg(41.8 kB)
inputdata.jpg(41.8 kB){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Now I want to aggregate the data set find count of CC_CD on the base of MANDT, GPART and VKONT ,so that the data set should appear to be
{kind=link}
I tried doing it by inputting the previous data set to an aggregation node taking MANDT , GPART , VKONT , CC_CD as attribute and summing it against DUMMY .But the result is 1 in the column sum(DUMMY).
I also tried by adding the column CC_CD as aggregated column (setting its property as COUNT) , still the count comes as 1 .
I am not getting the reason why in the aggregation AUGDT and FAEDN are taking part though I have not taken them in aggregation .
Thanks once again .
Best Regards
Rohit
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
- SAP Datasphere + SAP S/4HANA: Your Guide to Seamless Data Integration in Technology Blogs by SAP
- Elevating Customer Engagement: Harnessing the Power of SAP Chatbots for a Personalized Experience in Technology Blogs by Members
- SAP Datasphere - Space, Data Integration, and Data Modeling Best Practices in Technology Blogs by SAP
- Workload Analysis for HANA Platform Series - 2. Analyze the CPU, Threads and Numa Utilizations in Technology Blogs by SAP
- Analytical Query CDS View creation and consumption in RSRT along with publishing OData Services in Technology Blogs by Members
| User | Count |
|---|---|
| 69 | |
| 8 | |
| 8 | |
| 6 | |
| 6 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 5 |
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.